当我们在VS里面编译一个以UTF8保存的c源程序时,MSVC会将字符串的编码从UTF8转换为ANSI编码(当前系统的页代码)
我们通过运行以下代码进行测试
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
int main()
{
const char * str = "a哈は";
int i;
for (i = 0; i < strlen(str); i++)
printf("%02hhX ", (unsigned char)str[i]);
printf("\n%s\n", str);
system("pause");
return 0;
}"a哈は"如果在ANSI编码下的十六进制内容应该是:61 B9 FE A4 CF
在UTF-8编码下应该是:61 E5 93 88 E3 81 AF
在不同编码的不同环境运行下有以下的输出结果:
| 编译器 | UTF-8 BOM | UTF8 | ANSI |
| MSVC 14.0 | 61 B9 FE A4 CF(正常) | 61 E5 93 88 E3 81 AF(乱码) | 61 B9 FE A4 CF(正常) |
| mingw5.5 | 61 E5 93 88 E3 81 AF(乱码) | 61 E5 93 88 E3 81 AF(乱码) | 61 B9 FE A4 CF(正常) |
*Windows控制台默认编码(页代码)是GBK,输出内容不是GBK编码的都会是乱码
可以得出以下几个结论:
- 源程序不包含BOM头时,MSVC会认为程序的编码是当前的”执行字符集”即ANSI编码(当前系统的页代码是GBK)
这次的字符串在UTF8编码下恰好是6个字节,可以构成3个汉字,所以编译器没将后面的”(双引号)当作汉字的一部分处理。 如果内容是"aは"(61 E3 81 AF)编译时会将最后的AF与双引号(“)结合,然后就会有各种奇葩的错误了 - 当源程序含有UTF8 BOM头时,MSVC会认为程序是UTF8编码,遇到字符串时会把字符串转换为ANSI编码即当前系统的页代码(GBK)。所以实际上在运行时候,字符串还会是GBK编码。
- mingw在编译时,默认会将字符串和程序当作UTF8编码(这也是因为它是从unix系统移植过来的吧)
实际应用:
Qt中文乱码问题
在Qt中,如果我们有下面的代码
QMessageBox::information(NULL,"哈","は");在用MSVC编译器编译,默认情况下编译会出现错误(UTF8 无BOM):
mainwindow.cpp:-1: warning: C4819: 该文件包含不能在当前代码页(936)中表示的字符。请将该文件保存为 Unicode 格式以防止数据丢失
这是因为某个汉字的utf8编码被拆为若干个汉字,最后一个字符恰好跟双引号结合起来了。
如果程序是UTF8有BOM 编码,编译没有问题,但是运行时内容是乱码。
原因是在你传入一个字符串时候,Qt默认以UTF8编码*将char转为QChar。
*作者注:网上许多地方说默认是西欧编码,在5.10版本的Qt,官网的描述如下
Constructs a string initialized with the 8-bit string str. The given const char pointer is converted to Unicode using the fromUtf8() function.
大概意思是默认从UTF8编码转换为QString
You can disable this constructor by defining QT_NO_CAST_FROM_ASCII when you compile your applications. This can be useful if you want to ensure that all user-visible strings go through QObject::tr(), for example.
Note: Defining QT_RESTRICTED_CAST_FROM_ASCII also disables this constructor, but enables a QString(const char (&ch)[N]) constructor instead. Using non-literal input, or input with embedded NUL characters, or non-7-bit characters is undefined in this case.
如果声明常量QT_RESTRICTED_CAST_FROM_ASCII,那么输入的字符串应该都是ASCII字符,总而言之就是英文字符串。
小提示:
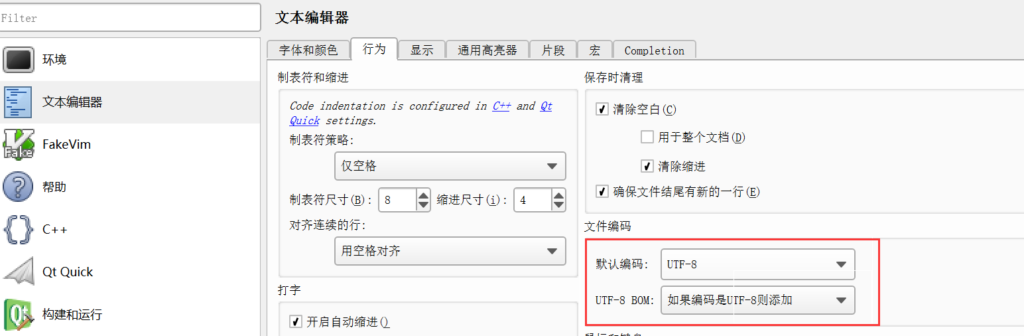
在Qt Creator的 工具->选项->文本编辑器->行为->文件编码 将UTF8-BOM选为 如果编码是UTF8则添加 然后保存文件可以为源文件添加BOM头
如果你打算用MSVC继续编译,本文列出以下几个解决方案:
一、在编译时加入编码选项(仅限VS2015 Update 2以上版本)(推荐!)
文件保存为UTF8格式(无论有没有BOM都可以)
在xxx.pro文件最下面加入下面代码:
QMAKE_CXXFLAGS += /source-charset:utf-8 /execution-charset:utf-8
然后在qt creator的 构建 -> 执行qmake 后再编译运行就正常了
二、在源文件加入编码选项(仅限VS2010以上版本)(比较推荐)
文件保存为UTF8带BOM格式
在含有非英文字符的文件最开头加入代码:
#pragma execution_character_set("utf-8")三、可以使用QString::fromLocal8Bit,那么Qt会将字符串从使用QTextCodec::codecForLocale设置的编码转为Unicode编码
使用举例:
#include <QTextCodec>
/*....*/
QTextCodec::setCodecForLocale(QTextCodec::codecForName("GBK"));//默认的Codec是System(当前系统的编码)
QMessageBox::information(NULL,QString::fromLocal8Bit("哈"),QString::fromLocal8Bit("は"));如果我们不设置QTextCodec::setCodecForLocale,那么我们的程序在非GBK环境下运行也可能会出现乱码